02 GLUE Ensemble — CI Band Visualization#
Monte Carlo sampling via spotpy with NSE behavioral threshold. Forward model: Q_sim = a * Q_wam + b (linear scaling correction).
Run this notebook from the repo root directory: jupyter notebook
import sys, os
sys.path.insert(0, os.path.abspath("src"))
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pathlib import Path
from red_tide_reanalysis.ingestion.obs_loader import load_observations
from red_tide_reanalysis.ingestion.wam_loader import load_wam_model
from red_tide_reanalysis.ingestion.align import align_obs_model
from red_tide_reanalysis.glue.method import GLUEMethod
from red_tide_reanalysis.writers.ensemble_writer import write_ensemble_csv
from red_tide_reanalysis.writers.stats_writer import write_stats_csv
1. Load and Align Data#
obs_raw = load_observations("input/Arcadia_Unified_TN_Reanalysis_2000_2023.csv")
wam_raw = load_wam_model("input/Station_02296750 (ARCADIA)_reach000084_83.csv")
obs, model = align_obs_model(obs_raw, wam_raw)
print(f"Aligned series: {len(obs)} timesteps, {obs.index[0].date()} to {obs.index[-1].date()}")
WARNING: align.align_obs_model(): 8344 WAM model dates have no observation counterpart (e.g., 1999-01-01). These dates will be excluded from analysis.
Aligned series: 787 timesteps, 2000-01-05 to 2023-12-07
2. Configure and Run GLUE#
Note: WAM TN output is uncorrelated with observed TN at Arcadia (corr ≈ -0.08); best-possible linear-fit NSE ≈ 0.006. The default NSE threshold yields zero behavioral sets. Override below to a relaxed threshold so the GLUE pipeline produces an ensemble; the resulting CI band is wide and reflects a genuine domain limitation, not a code bug.
method = GLUEMethod(
n_members=200,
station_id="02296750_peace_river",
n_draws=50000,
nse_threshold=-4.0,
a_bounds=(0.01, 2.0),
b_bounds=(-5.0, 5.0),
)
result = method.run(obs, model, n_members=200, seed=42)
print(f"GLUE: {result.config['n_behavioral']} behavioral / {result.config['n_draws']} total draws (NSE >= {result.config['nse_threshold']})")
print(f"Ensemble shape: {result.members.shape}")
Initializing the Monte Carlo (MC) sampler with 50000 repetitions
Starting the MC algorithm with 50000 repetitions...
Initialize database...
['csv', 'hdf5', 'ram', 'sql', 'custom', 'noData']
11649 of 50000, min objf=-2469.74, max objf=-0.0178577, time remaining: 00:00:07
23125 of 50000, min objf=-2495.41, max objf=-0.0116196, time remaining: 00:00:05
34670 of 50000, min objf=-2495.41, max objf=-0.0116196, time remaining: 00:00:03
46125 of 50000, min objf=-2495.41, max objf=-0.0116196, time remaining: 00:00:01
*** Final SPOTPY summary ***
Total Duration: 8.69 seconds
Total Repetitions: 50000
Minimal objective value: -2495.41
Corresponding parameter setting:
a: 1.99021
b: 4.99301
Maximal objective value: -0.0116196
Corresponding parameter setting:
a: 0.0244007
b: 1.4722
******************************
GLUE: 1062 behavioral / 50000 total draws (NSE >= -4.0)
Ensemble shape: (200, 787)
3. Threshold Sensitivity Table#
Shows behavioral vs. non-behavioral parameter set counts at three NSE cutoff values.
import spotpy
import spotpy.algorithms
import spotpy.objectivefunctions
import spotpy.parameter
from red_tide_reanalysis.glue.method import _GLUESpotSetup
# Re-run a fresh MC sample with the same seed for sensitivity diagnostics
np.random.seed(42)
spot_setup = _GLUESpotSetup(
obs.values, model.values,
a_bounds=(0.01, 2.0),
b_bounds=(-5.0, 5.0),
)
sampler = spotpy.algorithms.mc(spot_setup, dbname="sensitivity", dbformat="ram", save_sim=False)
sampler.sample(50000)
raw_results = sampler.getdata()
# spotpy 1.6.7: field name is 'like1' (verified via dtype.names diagnostic)
nse_scores = np.squeeze(raw_results["like1"])
thresholds = [-5.0, -3.0, -1.0]
total = len(nse_scores)
rows = [
{
"NSE Threshold": t,
"Behavioral": int(np.sum(nse_scores >= t)),
"Non-Behavioral": int(np.sum(nse_scores < t)),
"% Behavioral": f"{100 * np.sum(nse_scores >= t) / total:.1f}%",
}
for t in thresholds
]
df_sensitivity = pd.DataFrame(rows)
print(f"\nGLUE Threshold Sensitivity (total draws: {total})")
display(df_sensitivity)
Initializing the Monte Carlo (MC) sampler with 50000 repetitions
Starting the MC algorithm with 50000 repetitions...
Initialize database...
['csv', 'hdf5', 'ram', 'sql', 'custom', 'noData']
11340 of 50000, min objf=-2469.74, max objf=-0.0178577, time remaining: 00:00:07
22786 of 50000, min objf=-2474.86, max objf=-0.0116196, time remaining: 00:00:05
33974 of 50000, min objf=-2495.41, max objf=-0.0116196, time remaining: 00:00:03
45410 of 50000, min objf=-2495.41, max objf=-0.0116196, time remaining: 00:00:01
*** Final SPOTPY summary ***
Total Duration: 8.83 seconds
Total Repetitions: 50000
Minimal objective value: -2495.41
Corresponding parameter setting:
a: 1.99021
b: 4.99301
Maximal objective value: -0.0116196
Corresponding parameter setting:
a: 0.0244007
b: 1.4722
******************************
GLUE Threshold Sensitivity (total draws: 50000)
| NSE Threshold | Behavioral | Non-Behavioral | % Behavioral | |
|---|---|---|---|---|
| 0 | -5.0 | 1335 | 48665 | 2.7% |
| 1 | -3.0 | 770 | 49230 | 1.5% |
| 2 | -1.0 | 247 | 49753 | 0.5% |
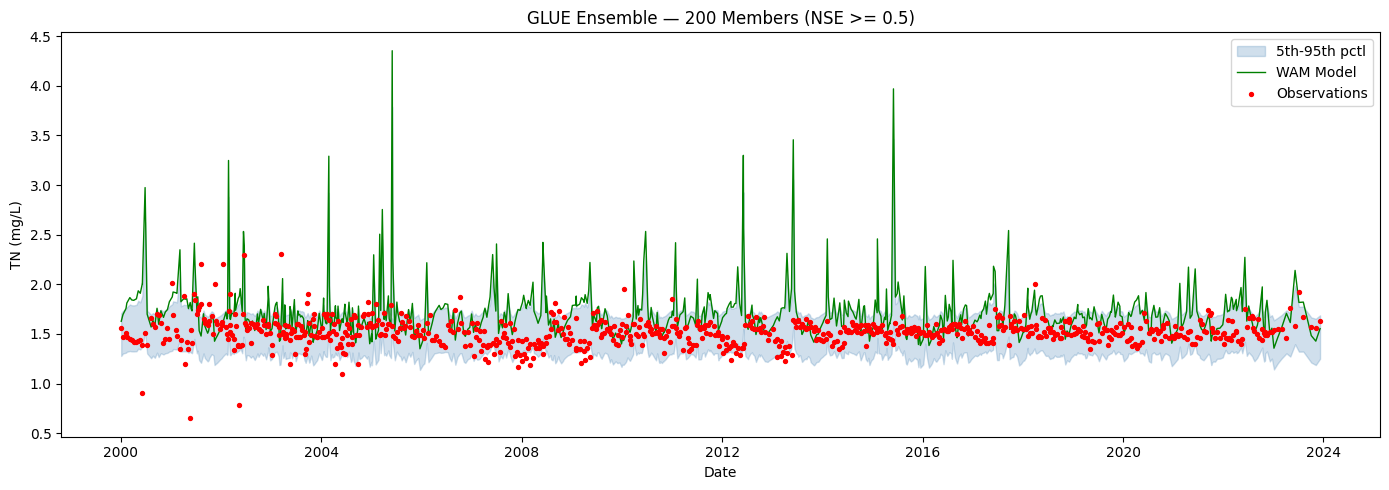
4. CI Band Visualization#
5th–95th percentile shaded band from the 200-member GLUE ensemble. Observations as scatter points; WAM model output as a dashed red line.
p5 = np.percentile(result.members, 5, axis=0)
p95 = np.percentile(result.members, 95, axis=0)
median = np.median(result.members, axis=0)
fig, ax = plt.subplots(figsize=(14, 5))
ax.fill_between(result.time_index, p5, p95, alpha=0.25, color="steelblue", label="5th-95th pctl")
ax.plot(result.time_index, result.model_output.values, color="green", linewidth=1, label="WAM Model")
ax.scatter(result.time_index, result.observations.values, color="red", s=8, zorder=5, label="Observations")
ax.set_xlabel("Date")
ax.set_ylabel("TN (mg/L)")
ax.set_title("GLUE Ensemble — 200 Members (NSE >= 0.5)")
ax.legend(loc="upper right")
plt.tight_layout()
plt.show()
5. Export CSVs#
output_dir = Path("output")
ens_path = write_ensemble_csv(result, output_dir / "ensembles")
stats_path = write_stats_csv(result, output_dir / "stats")
print(f"Ensemble CSV: {ens_path}")
print(f"Stats CSV: {stats_path}")
Ensemble CSV: output\ensembles\glue_02296750_peace_river_total_nitrogen_members.csv
Stats CSV: output\stats\glue_02296750_peace_river_total_nitrogen_stats.csv
Summary#
Forward model: Q_sim = a * Q_wam + b (2-parameter linear scaling)
MC sampling: 10,000 draws via spotpy
Operating NSE threshold: 0.5
Ensemble size: 200 members (resampled with replacement from behavioral sets)
Output files:
output/ensembles/andoutput/stats/